
Algorand node counting
Intro
One of the most challenging aspects of analyzing decentralized blockchain networks is accurately determining their size and distribution. Unlike centralized systems, where all participants are registered and known, blockchain networks consist of voluntary, pseudonymous nodes that can join or leave the network at any time. This creates significant challenges for researchers, network analysts, and the blockchain community who need reliable metrics about network composition.
This article explores a new approach to estimating the total number of full-time node equivalents in the Algorand blockchain by applying ecological sampling techniques — specifically, the Chao-1 estimator — using relay nodes as observation points. This methodology draws interesting parallels between biodiversity sampling in ecology and node discovery in distributed networks.
Counting the nodes the old way
As of Q2’25, Algorand does not yet operate as a fully meshed P2P network and uses designated relays to propagate gossip messages. Each node maintains websocket connections to four relays at a time. The connection that has the highest cumulative buffering delay is designated to be replaced with a new, random one every four minutes.
The original node counting method assumed that all nodes have somewhat static IP addresses and connect to the network using the default behaviour. A simple, unique IP count over 24-hour period across a sample of relays (observers) proved to be a good node count estimator.
With the influx of home nodes with ephemeral IP addresses as well as short-lived liquidator bot connections, the unique node count exploded in 2024, and especially in 2025 after the incentives program went live.
The challenge
The simplest solution would be to change the time 24-hour window and count unique nodes within shorter, 1-hour intervals. This approach, however, introduces new challenges:
- Short-lived bot connections account for a significant number of unique nodes and have high time-of-day variability.
- Nodes might not have enough time to randomly “hit” a designated set of observers, making the node counting highly dependent on the number of relays used for monitoring.
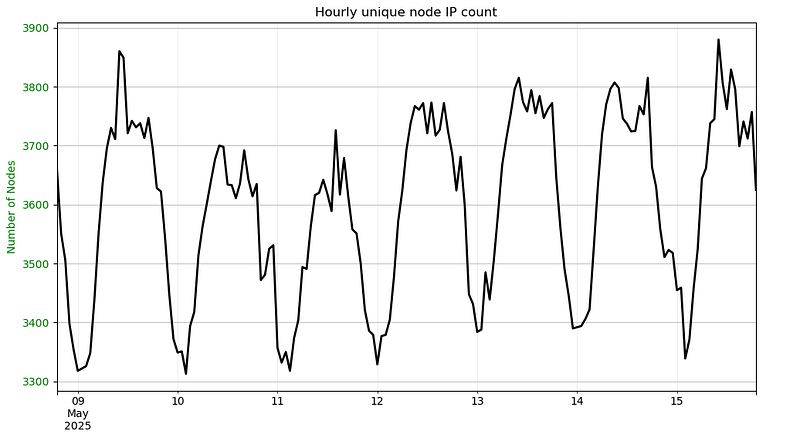
A unique node count no longer provides a meaningful number in the context of a network load or environmental impact (power consumption).
The new approach
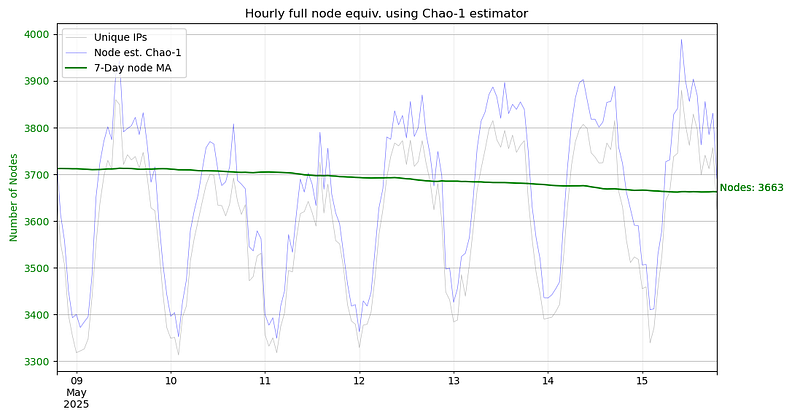
Let’s adopt a new KPI that counts full-time node equivalents instead of just counting ephemeral nodes. Such an indicator would more closely represent the actual size of the network and its environmental impact.
This can be solved by using a 7-day moving average of the hourly samples.
Accounting for a small or variable number of observers (relays) is a more complicated problem, similar to one that ecology researchers face when trying to estimate the total number of species in an environment without being able to count every individual. They’ve developed sophisticated statistical methods to estimate total population size based on limited samples. One such method is the Chao-1 estimator developed by Anne Chao and described in Non-parametric estimation of the classes in a population and Estimating the Population Size for Capture-Recapture Data with Unequal Catchability
The Chao-1 estimator provides a way to estimate the total number of species in a community based on the number of rare species found in a sample. The formula that allows for the calculation of the lower bound of a population size is elegantly simple:
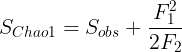
Where Sobs is the number of species (unique nodes) in the Sample,
F1 is the number of singletons (unique nodes seen by a one relay only),
F2 is the number of dubletons (unique nodes seen by two relays only).
This approach allows for a good lower bound estimate that does not depend on the number of observers (relays).
Methodolgy
Our approach adapts the Chao-1 estimator as well as sample filtering and averaging to the context of blockchain node counting:
- Observation Points: We select a limited number of relay nodes to serve as our “observation stations.” These relays are geographically distributed to minimize regional bias.
- Data Collection: Each relay node logs every IP address that connects to it over a one-hour period. This becomes our sampling interval. IP address information is stored as salted hashes for GDPR compliance.
- Data Filtering: We ignore nodes that fail to maintain a gossip connection for over a minute to mitigate Sybil attacks.
- Frequency Analysis: We analyze how many unique IP hashes were seen by exactly one relay, exactly two relays, and so on.
- Application of Chao-1: We apply the Chao-1 formula to the intervals to account for the limited number of observers.
- Temporal Analysis: We repeat this process for multiple one-hour windows to account for time-of-day variations in network activity. We apply a 7-day sliding average over the 1-hour node count estimates.
Limitations and Considerations
This methodology has several limitations that should be considered:
- IP Address ≠ Node: An IP address is not necessarily a 1:1 mapping to a node. Some nodes may share IP addresses (if behind NAT or CGNAT).
- Dynamic IPs: Some nodes may change their IP addresses more frequently than 1 hour, eg, due to link issues.
- Hidden Nodes: Nodes configured to connect to private relays would be undercounted.
- Sybil Attacks: The network may contain artificially created nodes that could skew the estimate.
- Relay Selection Bias: The choice of relay nodes for observation may introduce bias if they are not representative of the overall network.